Tutorial Aims:
- Learn about
Stan - Prepare a dataset for modelling
- Write a programme in
Stan - Run a
Stanprogramme - Specify priors in
Stan - Assess convergence diagnostics
All the files you need to complete this tutorial can be downloaded from this Github repository. Click on Clone/Download/Download ZIP and unzip the folder, or clone the repository to your own GitHub account.
This tutorial is based on work by Max Farrell - you can find Max’s original tutorial here which includes an explanation about how Stan works using simulated data, as well as information about model verification and comparison.
1. Learn about Stan
Bayesian modelling like any statistical modelling can require work to design the appropriate model for your research question and then to develop that model so that it meets the assumptions of your data and runs. You can check out the Coding Club tutorial on /tutorials/model-design/index.html, and Bayesian Modelling in MCMCglmm for key background information on model design and Bayesian statistics.
Statistical models can be fit in a variety of packages in R or other statistical languages. But sometimes the perfect model that you can design conceptually is very hard or impossible to implement in a package or programme that restricts the distributions and complexity that you can use. This is when you may want to move to a statistical programming language such as Stan.
Stan is a new-ish language that offers a more comprehensive approach to learning and implementing Bayesian models that can fit complex data structures. A goal of the Stan development team is to make Bayesian modelling more accessible with clear syntax, a better sampler (sampling here refers to drawing samples out of the Bayesian posterior distribution), and integration with many platforms and including R, RStudio, ggplot2, and Shiny.
In this introductory tutorial we’ll go through the iterative process of model building starting with a linear model. In our advanced Stan tutorial we will explore more complex model structures.
First, before building a model you need to define your question and get to know your data. Explore them, plot them, calculate some summary statistics.
Once you have a sense of your data and what question you want to answer with your statistical model, you can begin the iterative process of building a Bayesian model:
- Design your model.
- Choose priors (Informative? Not? Do you have external data you could turn into a prior?)
- Sample the posterior distribution.
- Inspect model convergence (traceplots, rhats, and for Stan no divergent transitions - we will go through these later in the tutorial)
- Critically assess the model using posterior predictions and checking how they compare to your data!
- Repeat…
It’s also good practice to simulate data to make sure your model is doing what you think it’s doing, as a further way to test your model!
2. Data
First, let’s find a dataset where we can fit a simple linear model. The National Snow and Ice Data Center provides loads of public data that you can download and explore. One of the most prominent climate change impacts on planet earth is the decline in annual sea ice extent in the Northern Hemisphere. Let’s explore how sea ice extent is changing over time using a linear model in Stan.
Set your working directory to the folder where you’ve saved the data by either clicking on Session/Set working directory/Choose directory or running the code setwd("your-file-path") with your own filepath inside. Now, let’s load the data:
# Adding stringsAsFactors = F means that numeric variables won't be
# read in as factors/categorical variables
seaice <- read.csv("seaice.csv", stringsAsFactors = F)
Let’s have a look at the data:
head(seaice)
If for some reason the column names are not read in properly, you can change column names using:
colnames(seaice) <- c("year", "extent_north", "extent_south")
What research question can we ask with these data? How about the following:
Research Question: Is sea ice extent declining in the Northern Hemisphere over time?
To explore the answer to that question, first we can make a figure.
plot(extent_north ~ year, pch = 20, data = seaice)
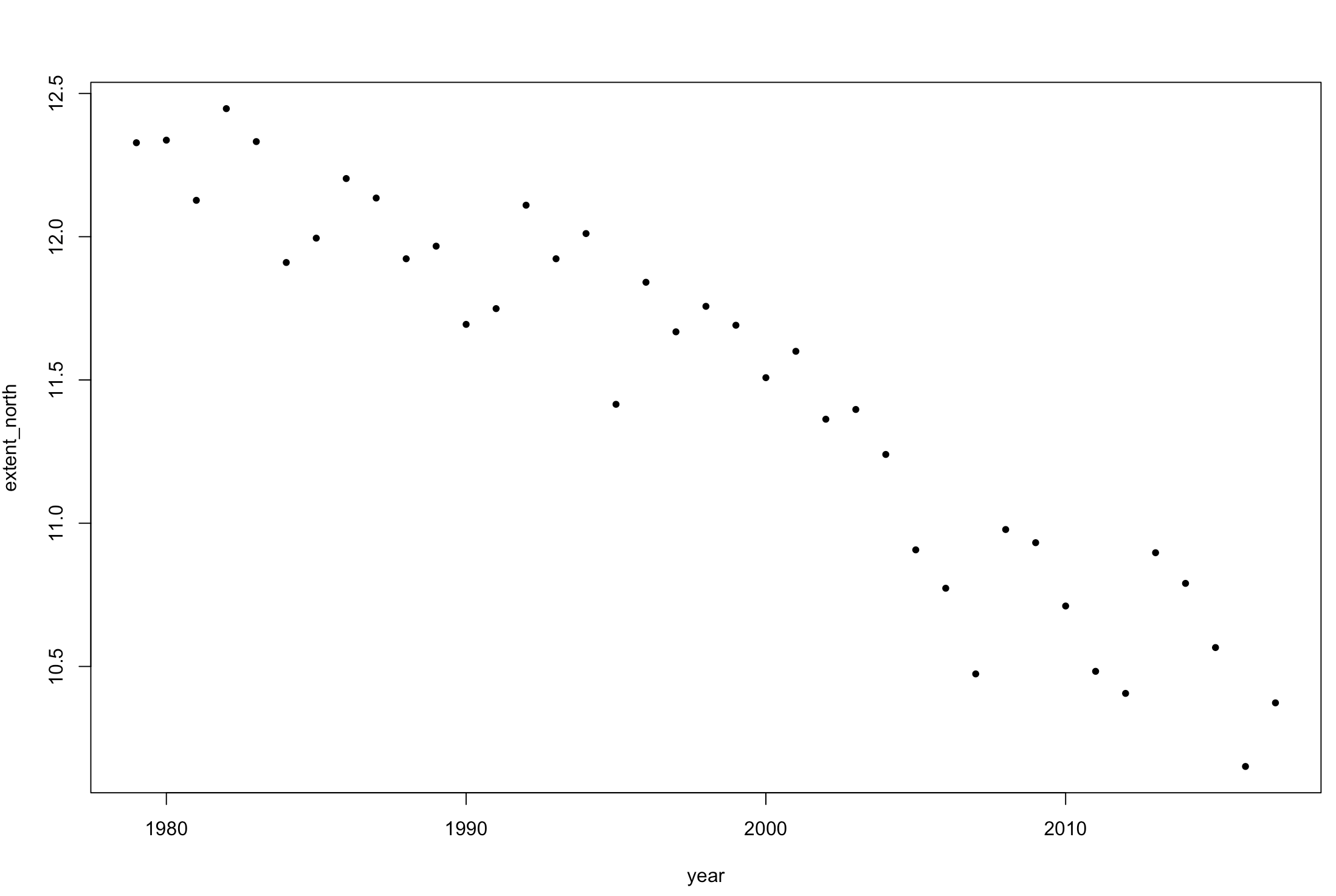 Figure 1. Change in sea ice extent in the Northern Hemisphere over time.
Figure 1. Change in sea ice extent in the Northern Hemisphere over time.
Now, let’s run a general linear model using lm().
lm1 <- lm(extent_north ~ year, data = seaice)
summary(lm1)
We can add that model fit to our plot:
abline(lm1, col = 2, lty = 2, lw = 3)
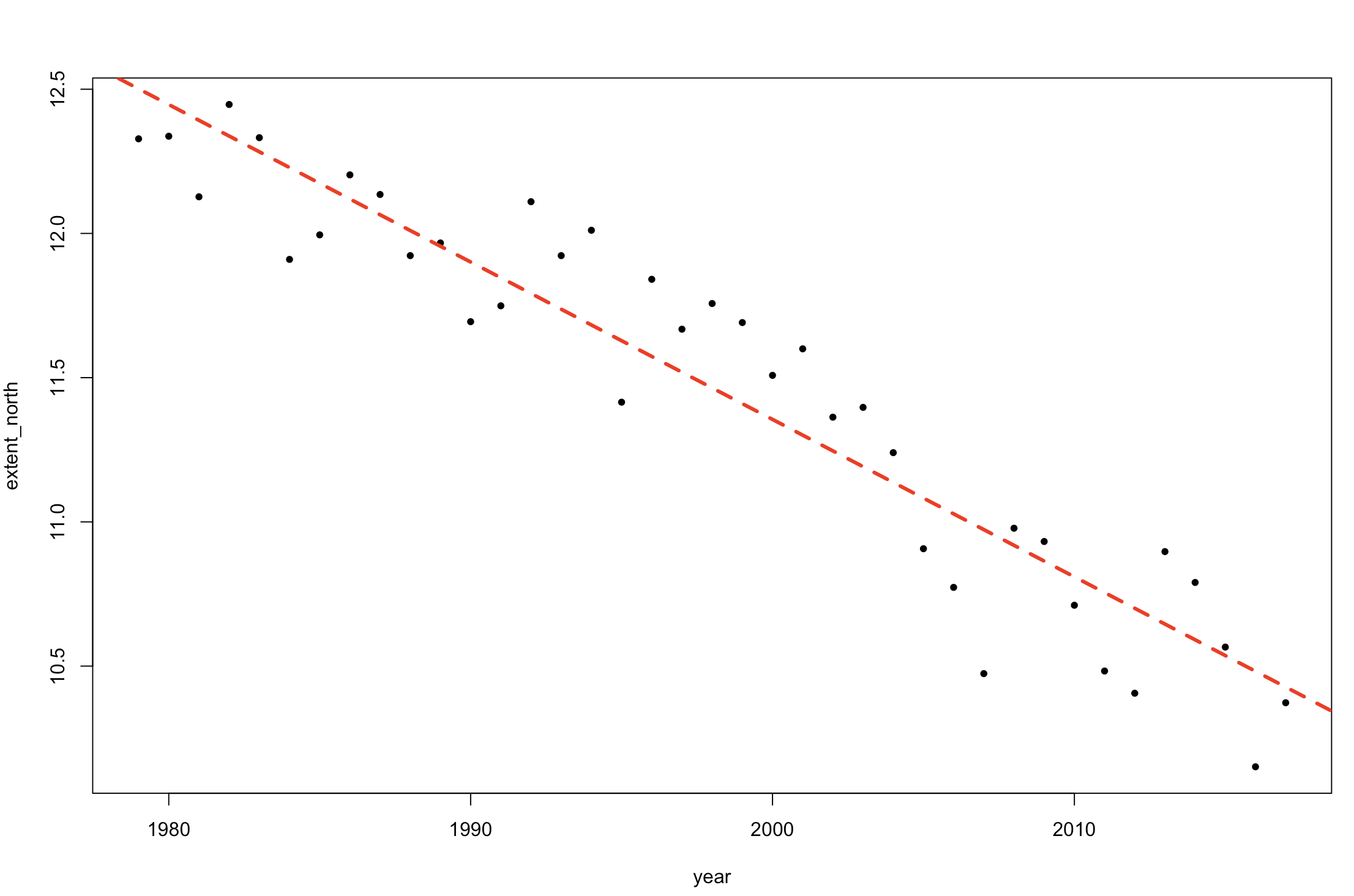 Figure 2. Change in sea ice extent in the Northern Hemisphere over time (plus linear model fit).
Figure 2. Change in sea ice extent in the Northern Hemisphere over time (plus linear model fit).
Let’s remember the equation for a linear model:
y = α + β∗x + error
In Stan you need to specify the equation that you are trying to model, so thinking about that model equation is key!
We have the answer to our question perhaps, but the point of this tutorial is to explore using the programming language Stan, so now let’s try writing the same model in Stan.
Preparing the data
Let’s rename the variables and index the years from 1 to 39. One critical thing about Bayesian models is that you have to describe the variation in your data with informative distributions. Thus, you want to make sure that your data do conform to those distributions and that they will work with your model. In this case, we really want to know is sea ice changing from the start of our dataset to the end of our dataset, not specifically the years 1979 to 2017 which are really far from the year 0. We don’t need our model to estimate what sea ice was like in the year 500, or 600, just over the duration of our dataset. So we set up our year data to index from 1 to 30 years.
x <- I(seaice$year - 1978)
y <- seaice$extent_north
N <- length(seaice$year)
We can re-run that linear model with our new data.
lm1 <- lm(y ~ x)
summary(lm1)
We can also extract some of the key summary statistics from our simple model, so that we can compare them with the outputs of the Stan models later.
lm_alpha <- summary(lm1)$coeff[1] # the intercept
lm_beta <- summary(lm1)$coeff[2] # the slope
lm_sigma <- sigma(lm1) # the residual error
Now let’s turn that into a dataframe for inputting into a Stan model. Data passed to Stan needs to be a list of named objects. The names given here need to match the variable names used in the models (see the model code below).
stan_data <- list(N = N, x = x, y = y)
Libraries
Please make sure the following libraries are installed (these are the libraries for this and the next Stan tutorial). rstan is the most important, and requires a little extra if you dont have a C++ compiler.
You can find detailed instructions here.
library(rstan)
library(gdata)
library(bayesplot)
3. Our first Stan program
We’re going to start by writing a linear model in the language Stan. This can be written in your R script, or saved seprately as a .stan file and called into R.
A Stan program has three required “blocks”:
- “data” block: where you declare the data types, their dimensions, any restrictions (i.e. upper = or lower = , which act as checks for
Stan), and their names. Any names you give to yourStanprogram will also be the names used in other blocks. - “parameters” block: This is where you indicate the parameters you want to model, their dimensions, restrictions, and name. For a linear regression, we will want to model the intercept, any slopes, and the standard deviation of the errors around the regression line.
- “model” block: This is where you include any sampling statements, including the “likelihood” (model) you are using. The model block is where you indicate any prior distributions you want to include for your parameters. If no prior is defined,
Stanuses default priors with the specificationsuniform(-infinity, +infinity). You can restrict priors using upper or lower when declaring the parameters (i.e.lower = 0> to make sure a parameter is positive). You can find more information about prior specification here.
Sampling is indicated by the ~ symbol, and Stan already includes many common distributions as vectorized functions. You can check out the manual for a comprehensive list and more information on the optional blocks you could include in your Stan model.
There are also four optional blocks:
- “functions”
- “transformed data”
- “transformed parameters”
- “generated quantities”
Comments are indicated by // in Stan. The write("model code", "file_name") bit allows us to write the Stan model in our R script and output the file to the working directory (or you can set a different file path).
write("// Stan model for simple linear regression
data {
int < lower = 1 > N; // Sample size
vector[N] x; // Predictor
vector[N] y; // Outcome
}
parameters {
real alpha; // Intercept
real beta; // Slope (regression coefficients)
real < lower = 0 > sigma; // Error SD
}
model {
y ~ normal(alpha + x * beta , sigma);
}
generated quantities {
} // The posterior predictive distribution",
"stan_model1.stan")
First, we should check our Stan model to make sure we wrote a file.
stanc("stan_model1.stan")
Now let’s save that file path.
stan_model1 <- "stan_model1.stan"
Here we are implicitly using uniform(-infinity, +infinity) priors for our parameters. These are also known as “flat” priors. Weakly informative priors (e.g. normal(0, 10) are more restricted than flat priors. You can find more information about prior specification here.
4. Running our Stan model
Stan programs are complied to C++ before being used. This means that the C++ code needs to be run before R can use the model. For this you must have a C++ compiler installed (see this wiki if you don’t have one already). You can use your model many times per session once you compile it, but you must re-compile when you start a new R session. There are many C++ compilers and they are often different across systems. If your model spits out a bunch of errors (unintelligible junk), don’t worry. As long as your model can be used with the stan() function, it compiled correctly. If we want to use a previously written .stan file, we use the file argument in the stan_model() function.
We fit our model by using the stan() function, and providing it with the model, the data, and indicating the number of iterations for warmup (these iterations won’t be used for the posterior distribution later, as they were just the model “warming up”), the total number of iterations, how many chains we want to run, the number of cores we want to use (Stan is set up for parallelization), which indicates how many chains are run simultaneously (i.e., if you computer has four cores, you can run one chain on each, making for four at the same time), and the thinning, which is how often we want to store our post-warmup iterations. “thin = 1” will keep every iteration, “thin = 2” will keep every second, etc…
Stan automatically uses half of the iterations as warm-up, if the warmup = argument is not specified.
fit <- stan(file = stan_model1, data = stan_data, warmup = 500, iter = 1000, chains = 4, cores = 2, thin = 1)
Accessing the contents of a stanfit object
Results from stan() are saved as a stanfit object (S4 class). You can find more details in the Stan vignette: [https://cran.r-project.org/web/packages/rstan/vignettes/stanfit-objects.html].
We can get summary statistics for parameter estimates, and sampler diagnostics by executing the name of the object:
fit

What does the model output show you? How do you know your model has converged? Can you see that text indicating that your C++ compiler has run?
From this output we can quickly assess model convergence by looking at the Rhat values for each parameter. When these are at or near 1, the chains have converged. There are many other diagnostics, but this is an important one for Stan.
We can also look at the full posterior of our parameters by extracting them from the model object. There are many ways to view the posterior.
posterior <- extract(fit)
str(posterior)
extract() puts the posterior estimates for each parameter into a list.
Let’s compare to our previous estimate with “lm”:
plot(y ~ x, pch = 20)
abline(lm1, col = 2, lty = 2, lw = 3)
abline( mean(posterior$alpha), mean(posterior$beta), col = 6, lw = 2)
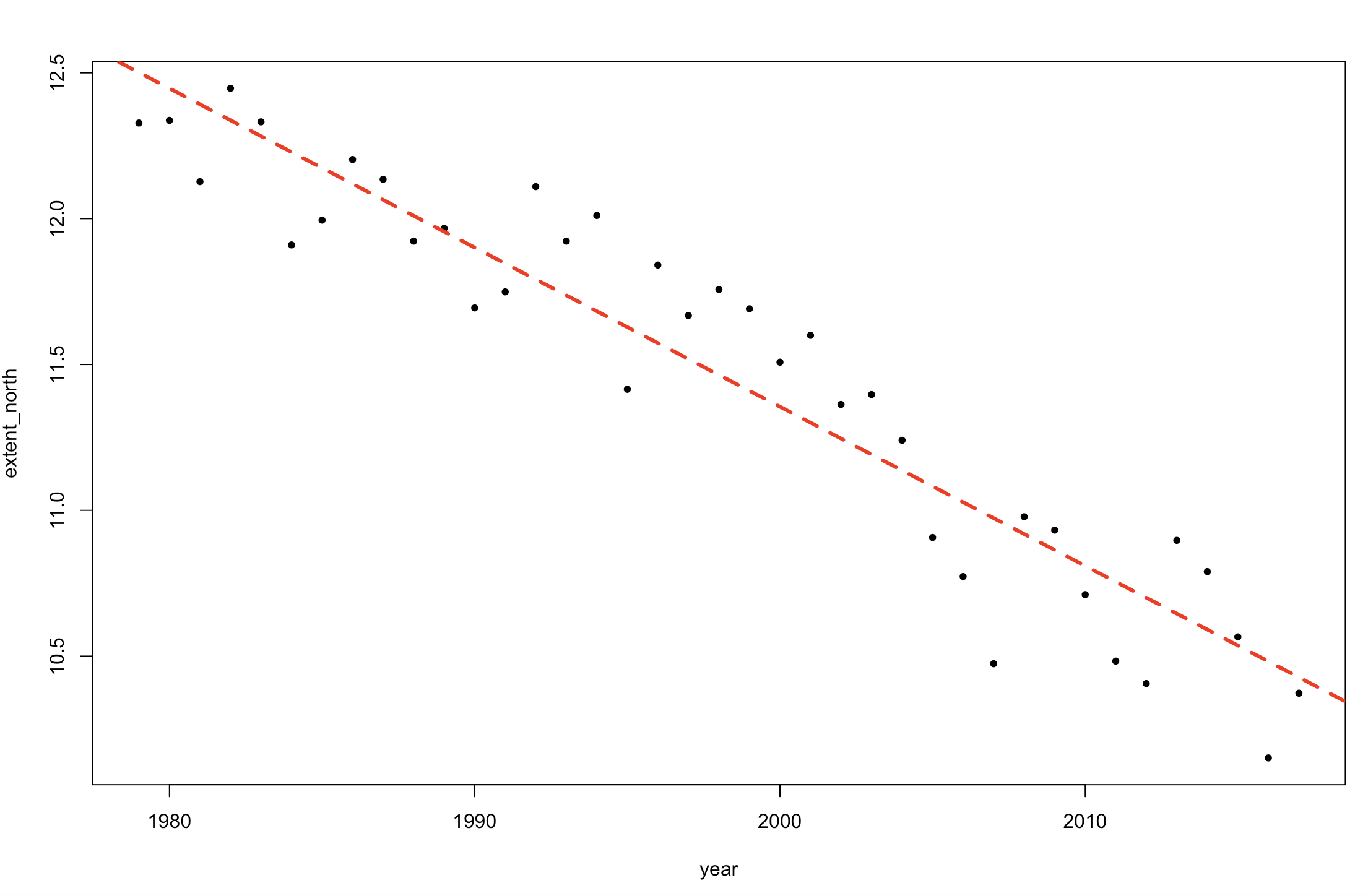
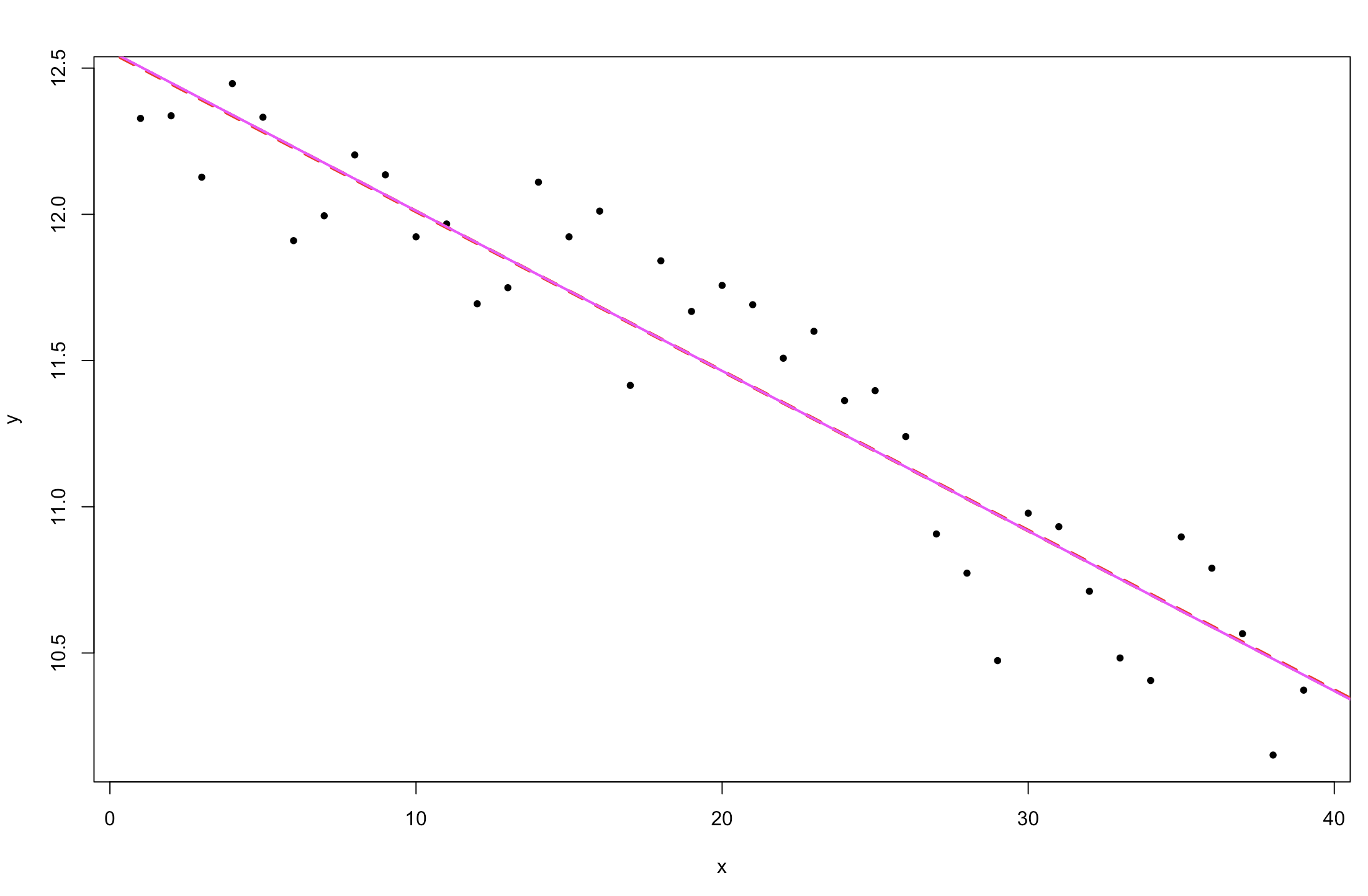
Figure 3. Change in sea ice extent in the Northern Hemisphere over time (comparing a Stan linear model fit and a general lm fit).
The result is identical to the lm output. This is because we are using a simple model, and have put non-informative priors on our parameters.
One way to visualize the variability in our estimation of the regression line is to plot multiple estimates from the posterior.
for (i in 1:500) {
abline(posterior$alpha[i], posterior$beta[i], col = "gray", lty = 1)
}
plot(y ~ x, pch = 20)
for (i in 1:500) {
abline(posterior$alpha[i], posterior$beta[i], col = "gray", lty = 1)
}
abline(mean(posterior$alpha), mean(posterior$beta), col = 6, lw = 2)
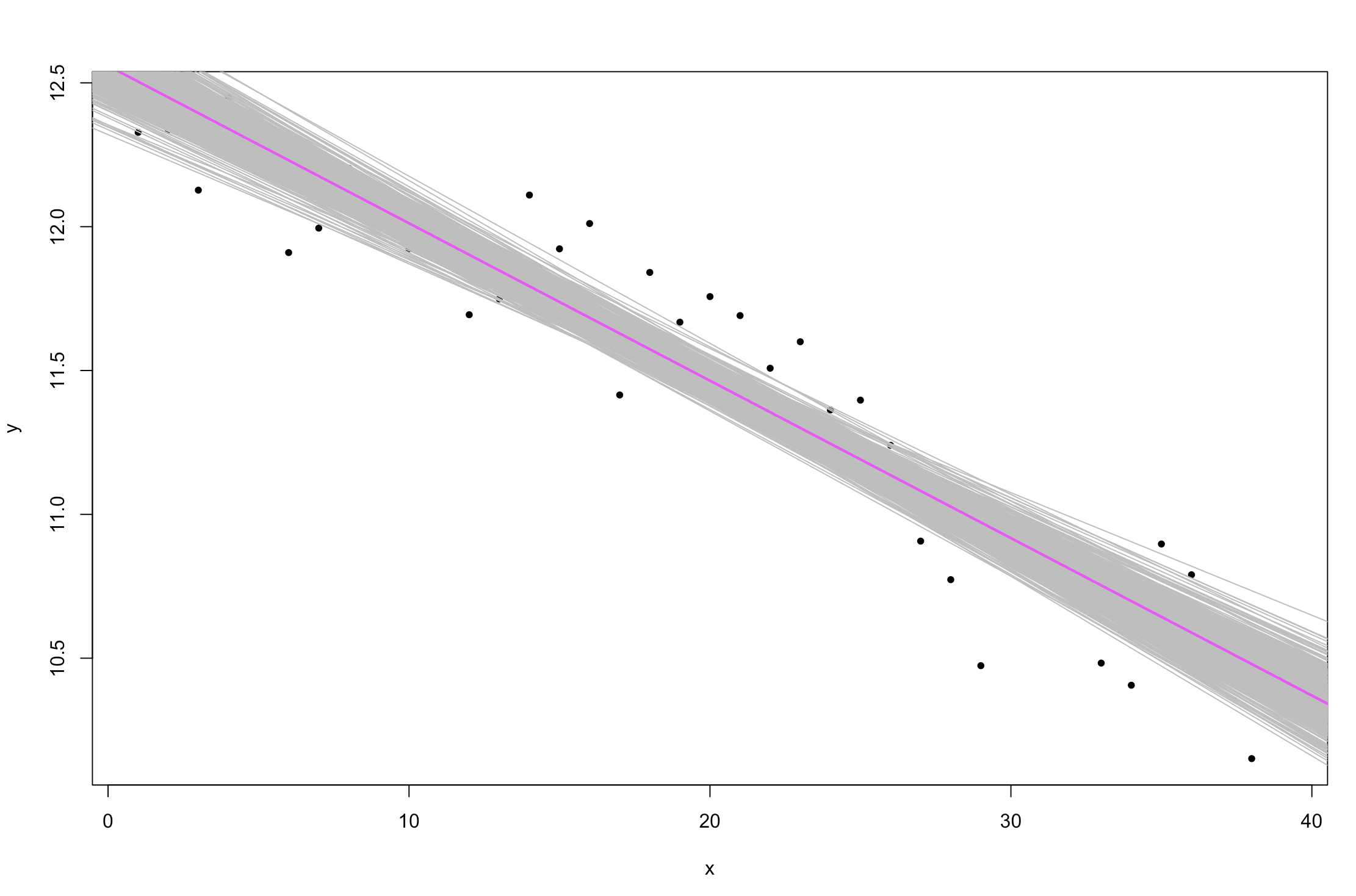 Figure 4. Change in sea ice extent in the Northern Hemisphere over time (
Figure 4. Change in sea ice extent in the Northern Hemisphere over time (Stan linear model fits).
5. Changing our priors
Let’s try again, but now with more informative priors for the relationship between sea ice and time. We’re going to use normal priors with small standard deviations. If we were to use normal priors with very large standard deviations (say 1000, or 10,000), they would act very similarly to uniform priors.
write("// Stan model for simple linear regression
data {
int < lower = 1 > N; // Sample size
vector[N] x; // Predictor
vector[N] y; // Outcome
}
parameters {
real alpha; // Intercept
real beta; // Slope (regression coefficients)
real < lower = 0 > sigma; // Error SD
}
model {
alpha ~ normal(10, 0.1);
beta ~ normal(1, 0.1);
y ~ normal(alpha + x * beta , sigma);
}
generated quantities {}",
"stan_model2.stan")
stan_model2 <- "scripts/users/imyerssmith/CC-Stan-Part-1/stan_model2.stan"
We’ll fit this model and compare it to the mean estimate using the uniform priors.
fit2 <- stan(stan_model2, data = stan_data, warmup = 500, iter = 1000, chains = 4, cores = 2, thin = 1)
posterior2 <- extract(fit2)
plot(y ~ x, pch = 20)
abline(alpha, beta, col = 4, lty = 2, lw = 2)
abline(mean(posterior2$alpha), mean(posterior2$beta), col = 3, lw = 2)
abline(mean(posterior$alpha), mean(posterior$beta), col = 36, lw = 3)
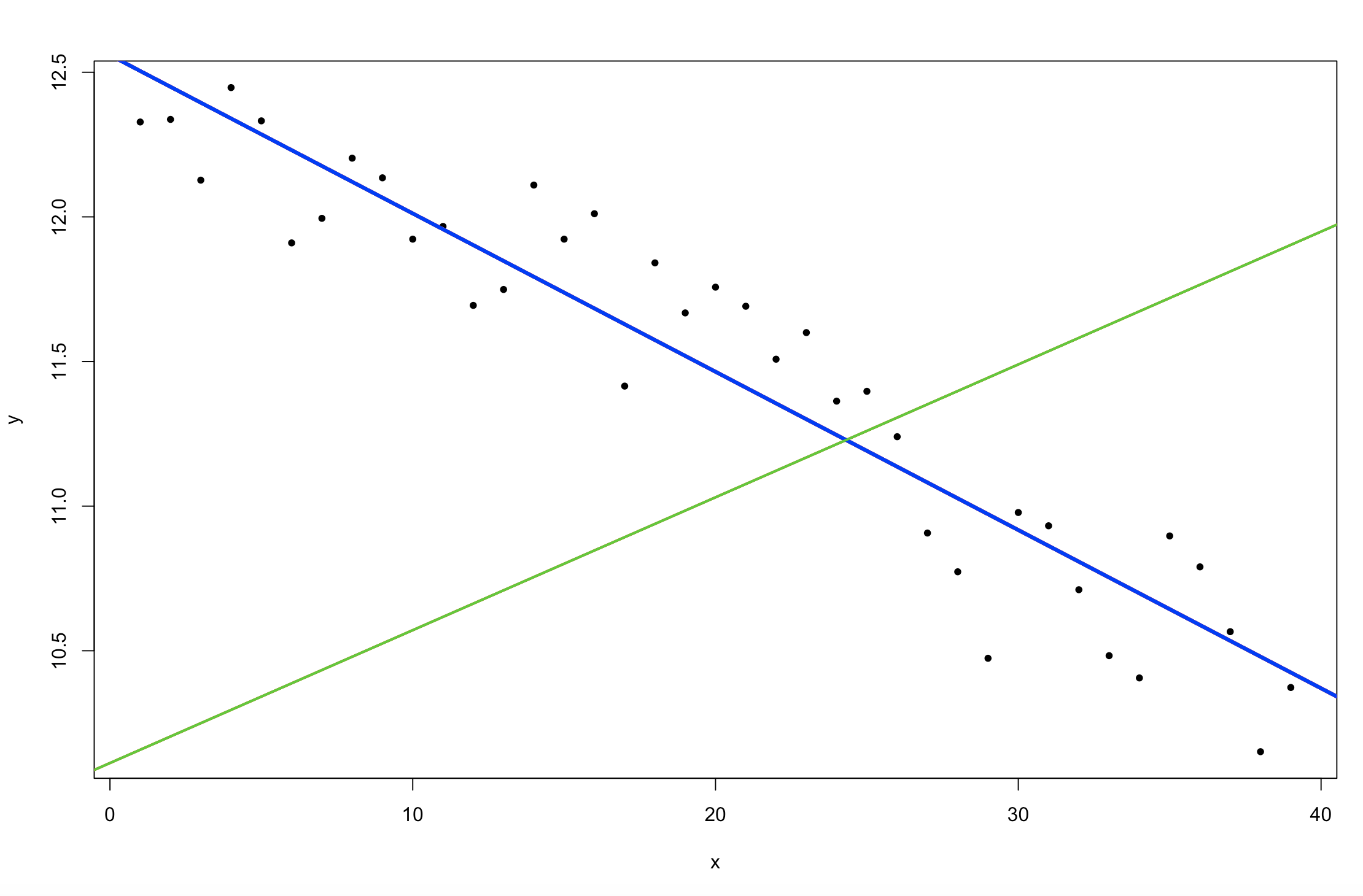 Figure 5. Change in sea ice extent in the Northern Hemisphere over time (
Figure 5. Change in sea ice extent in the Northern Hemisphere over time (Stan linear model fits).
So what happened to the posterior predictions (your modelled relationship)? Does the model fit the data better or not? Why did the model fit change? What did we actually change about our model by making very narrow prior distributions? Try changing the priors to some different numbers yourself and see what happens! This is a common issue in Bayesian modelling, if your prior distributions are very narrow and yet don’t fit your understanding of the system or the distribution of your data, you could run models that do not meaningfully explain variation in your data. However, that isn’t to say that you shouldn’t choose somewhat informative priors, you do want to use previous analyses and understanding of your study system inform your model priors and design. You just need to think carefully about each modelling decision you make!
6. Convergence Diagnostics
Before we go on, we should check again the Rhat values, the effective sample size (n_eff), and the traceplots of our model parameters to make sure the model has converged and is reliable. To find out more about what effective sample sizes and trace plots, you can check out the tutorial on Bayesian statistics using MCMCglmm.
n_eff is a crude measure of the effective sample size. You usually only need to worry is this number is less than 1/100th or 1/1000th of
your number of iterations.
'Anything over an `n_eff` of 100 is usually "fine"' - Bob Carpenter
For traceplots, we can view them directly from the posterior:
plot(posterior$alpha, type = "l")
plot(posterior$beta, type = "l")
plot(posterior$sigma, type = "l")
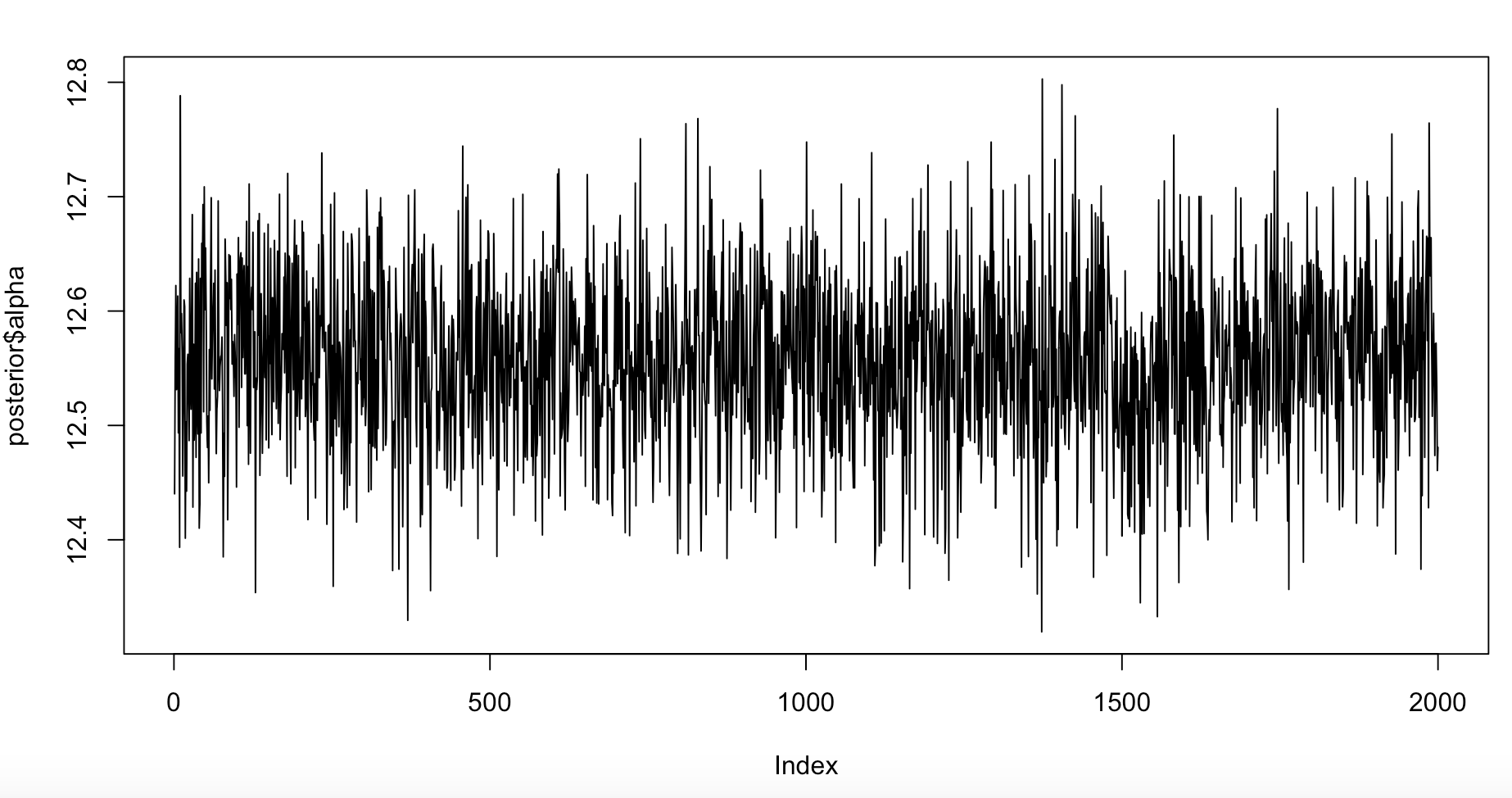 Figure 6. Trace plot for alpha, the intercept.
Figure 6. Trace plot for alpha, the intercept.
For simpler models, convergence is usually not a problem unless you have a bug in your code, or run your sampler for too few iterations.
Poor convergence
Try running a model for only 50 iterations and check the traceplots.
fit_bad <- stan(stan_model1, data = stan_data, warmup = 25, iter = 50, chains = 4, cores = 2, thin = 1)
posterior_bad <- extract(fit_bad)
This also has some “divergent transitions” after warmup, indicating a mis-specified model, or that the sampler that has failed to fully sample the posterior (or both!). Divergent transitions sound like some sort of teen fiction about a future dystopia, but actually it indicates problems with your model.
plot(posterior_bad$alpha, type = "l")
plot(posterior_bad$beta, type = "l")
plot(posterior_bad$sigma, type = "l")
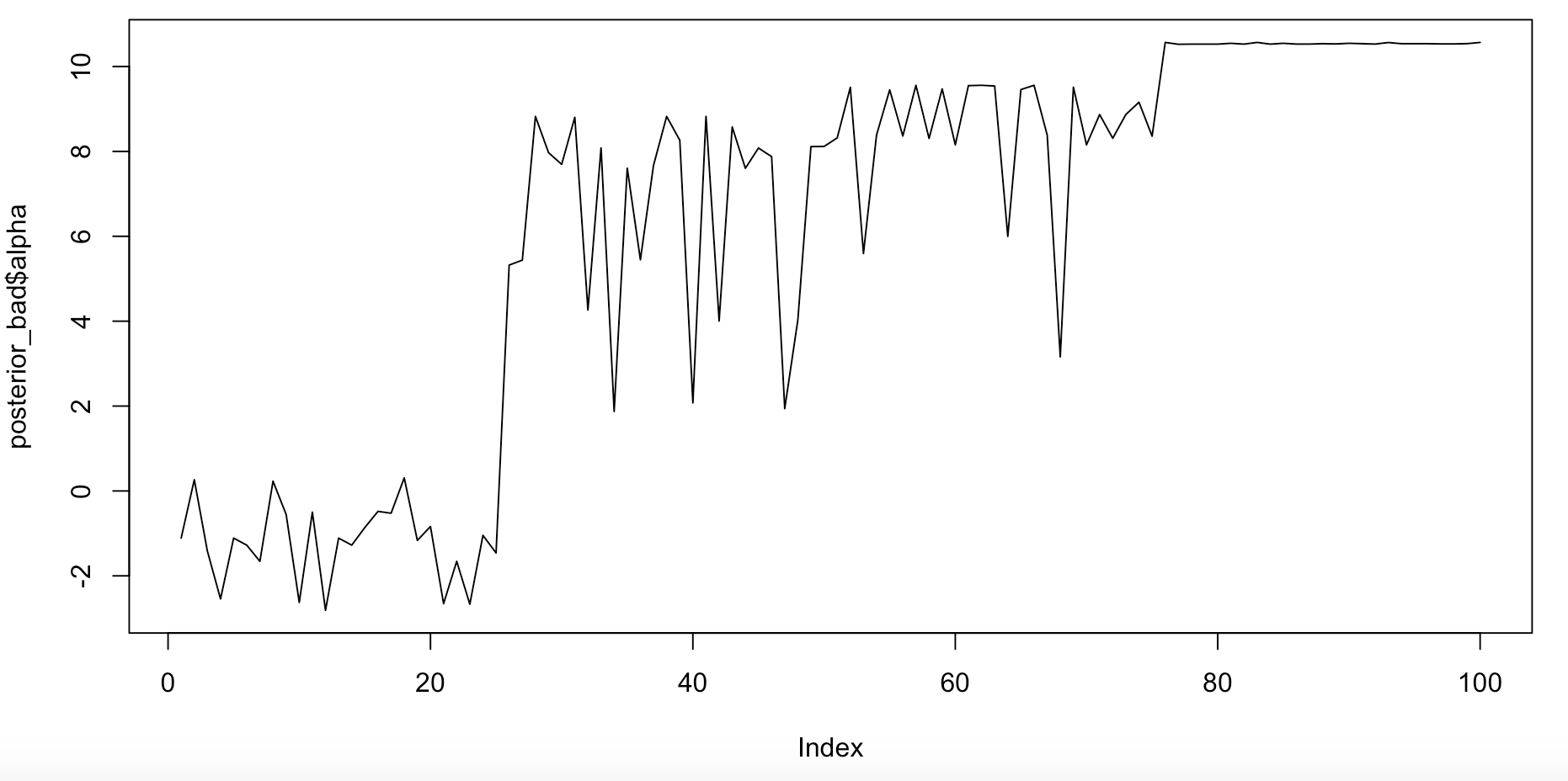 Figure 7. Bad trace plot for alpha, the intercept.
Figure 7. Bad trace plot for alpha, the intercept.
Parameter summaries
We can also get summaries of the parameters through the posterior directly. Let’s also plot the non-Bayesian linear model values to make sure our model is doing what we think it is…
par(mfrow = c(1,3))
plot(density(posterior$alpha), main = "Alpha")
abline(v = lm_alpha, col = 4, lty = 2)
plot(density(posterior$beta), main = "Beta")
abline(v = lm_beta, col = 4, lty = 2)
plot(density(posterior$sigma), main = "Sigma")
abline(v = lm_sigma, col = 4, lty = 2)
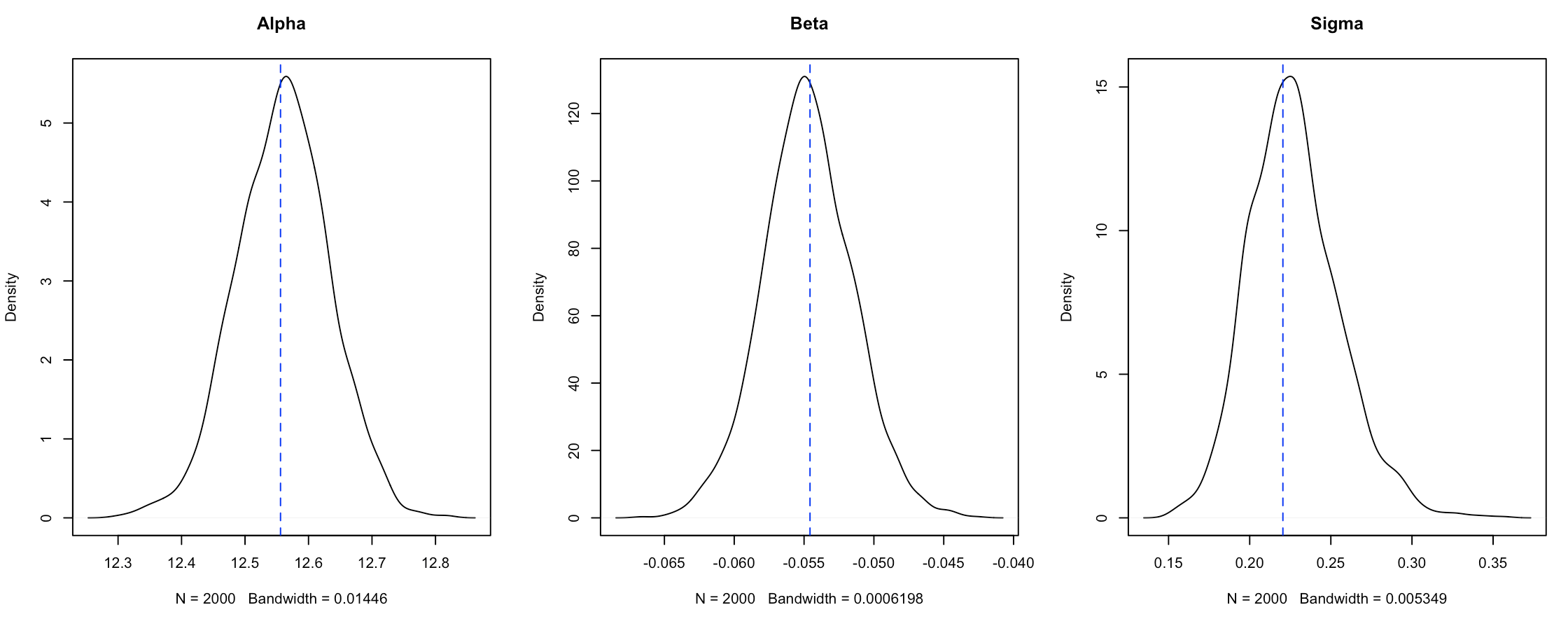 Figure 8. Density plot distributions from the
Figure 8. Density plot distributions from the Stan model fit compared with the estimates from the general lm fit.
From the posterior we can directly calculate the probability of any parameter being over or under a certain value of interest.
Probablility that beta is >0:
sum(posterior$beta>0)/length(posterior$beta)
# 0
Probablility that beta is >0.2:
sum(posterior$beta>0.2)/length(posterior$beta)
# 0
Diagnostic plots in rstan
While we can work with the posterior directly, rstan has a lot of useful functions built-in.
traceplot(fit)
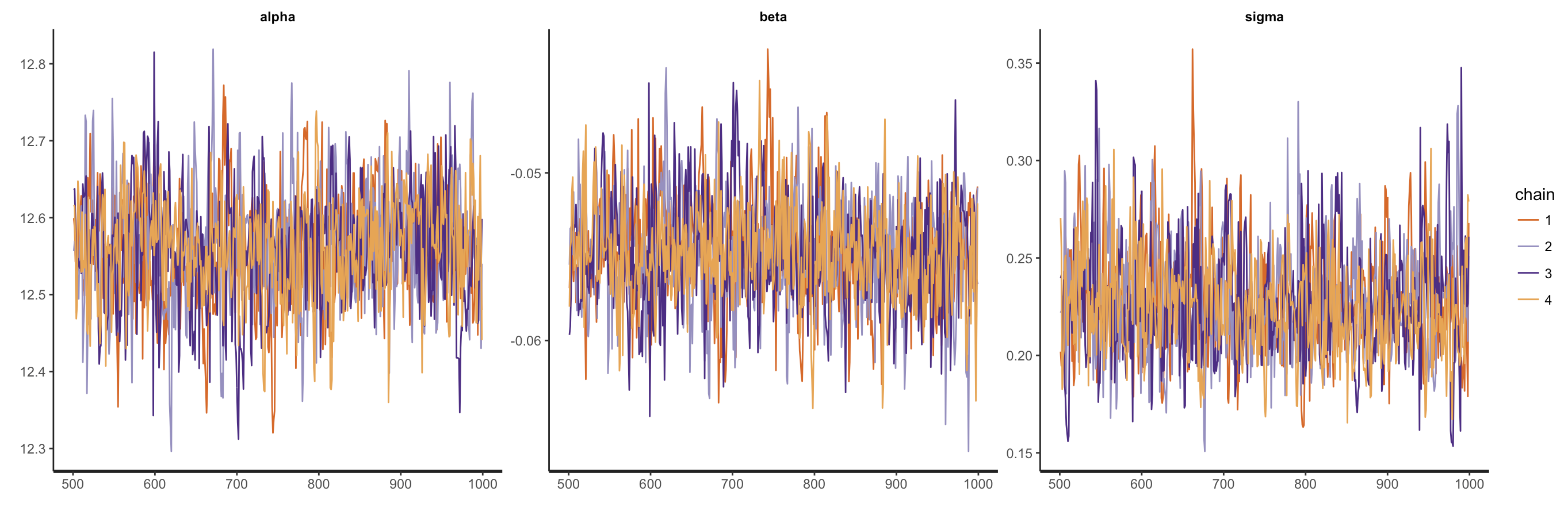 Figure 9. Trace plots of the different chains of the
Figure 9. Trace plots of the different chains of the Stan model.
This is a wrapper for the stan_trace() function, which is much better than our previous plot because it allows us to compare the chains.
We can also look at the posterior densities & histograms.
stan_dens(fit)
stan_hist(fit)
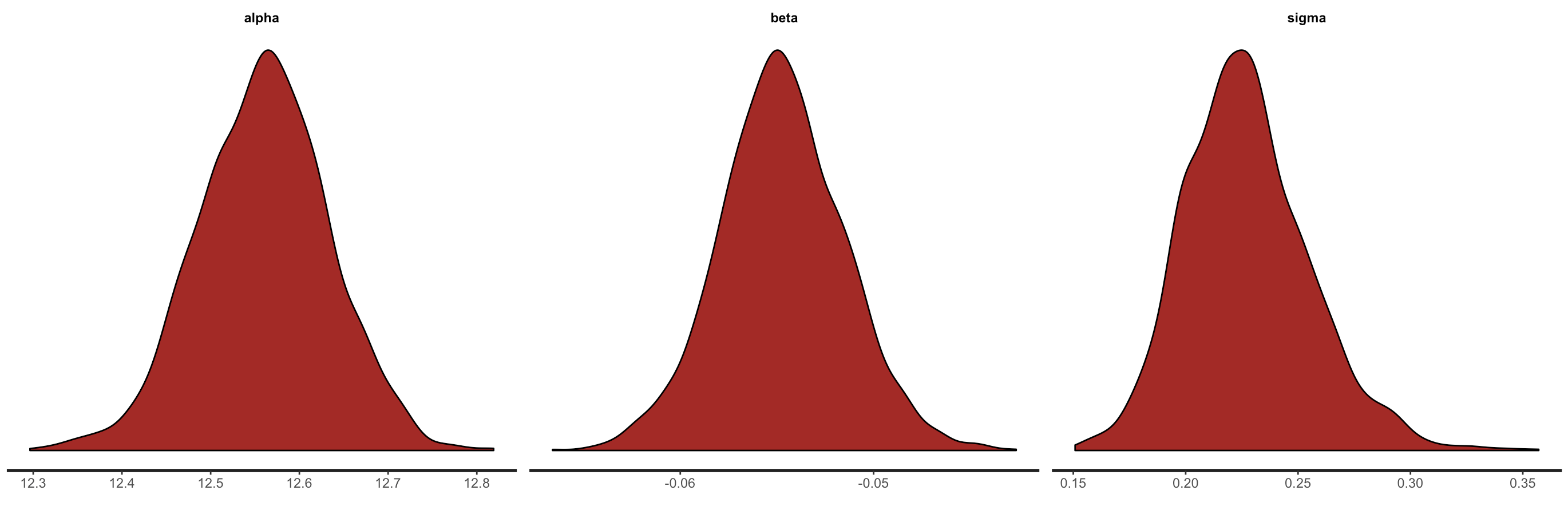
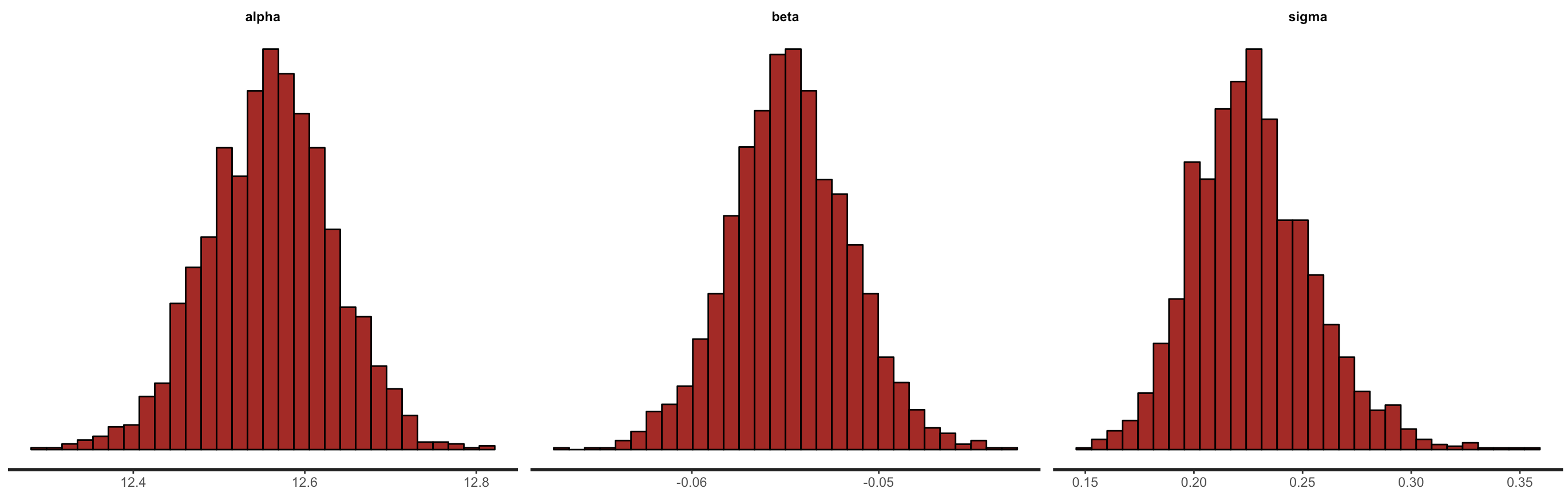 Figure 10. Density plots and histograms of the posteriors for the intercept, slope and residual variance from the
Figure 10. Density plots and histograms of the posteriors for the intercept, slope and residual variance from the Stan model.
And we can generate plots which indicate the mean parameter estimates and any credible intervals we may be interested in. Note that the 95% credible intervals for the beta and sigma parameters are very small, thus you only see the dots. Depending on the variance in your own data, when you do your own analyses, you might see smaller or larger credible intervals.
plot(fit, show_density = FALSE, ci_level = 0.5, outer_level = 0.95, fill_color = "salmon")
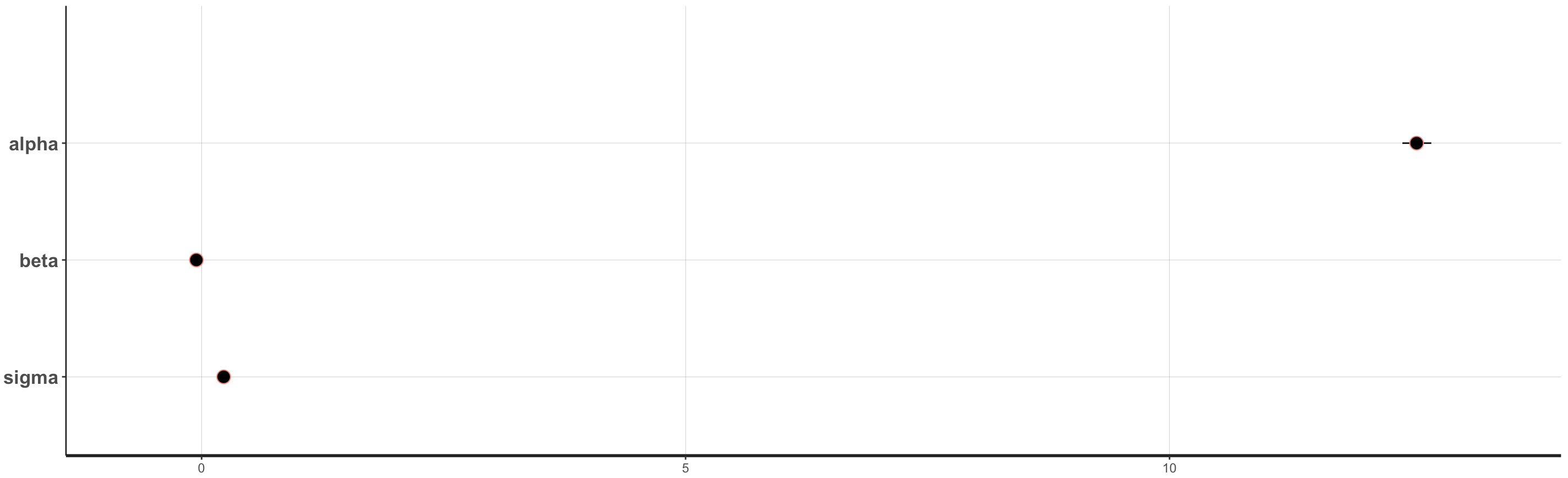 Figure 11. Parameter estimates from the
Figure 11. Parameter estimates from the Stan model.
Posterior Predictive Checks
For prediction and as another form of model diagnostic, Stan can use random number generators to generate predicted values for each data point, at each iteration. This way we can generate predictions that also represent the uncertainties in our model and our data generation process. We generate these using the Generated Quantities block. This block can be used to get any other information we want about the posterior, or make predictions for new data.
write("// Stan model for simple linear regression
data {
int < lower = 1 > N; // Sample size
vector[N] x; // Predictor
vector[N] y; // Outcome
}
parameters {
real alpha; // Intercept
real beta; // Slope (regression coefficients)
real < lower = 0 > sigma; // Error SD
}
model {
y ~ normal(x * beta + alpha, sigma);
}
generated quantities {
real y_rep[N];
for (n in 1:N) {
y_rep[n] = normal_rng(x[n] * beta + alpha, sigma);
}
}",
"stan_model2_GQ.stan")
stan_model2_GQ <- "scripts/users/imyerssmith/CC-Stan-Part-1/stan_model2_GQ.stan"
Note that vectorization is not supported in the GQ (generated quantities) block, so we have to put it in a loop. But since this is compiled to C++, loops are actually quite fast and Stan only evaluates the GQ block once per iteration, so it won’t add too much time to your sampling. Typically, the data generating functions will be the distributions you used in the model block but with an _rng suffix. (Double-check in the Stan manual to see which sampling statements have corresponding rng functions already coded up.)
fit3 <- stan(stan_model2_GQ, data = stan_data, iter = 1000, chains = 4, cores = 2, thin = 1)
Extracting the y_rep values from posterior.
There are many options for dealing with y_rep values.
y_rep <- as.matrix(fit3, pars = "y_rep")
dim(y_rep)
Each row is an iteration (single posterior estimate) from the model.
We can use the bayesplot package to make some prettier looking plots. This package is a wrapper for many common ggplot2 plots, and has a lot of built-in functions to work with posterior predictions. For details, you can check out the bayesplot vignettes.
Comparing density of y with densities of y over 200 posterior draws.
ppc_dens_overlay(y, y_rep[1:200, ])
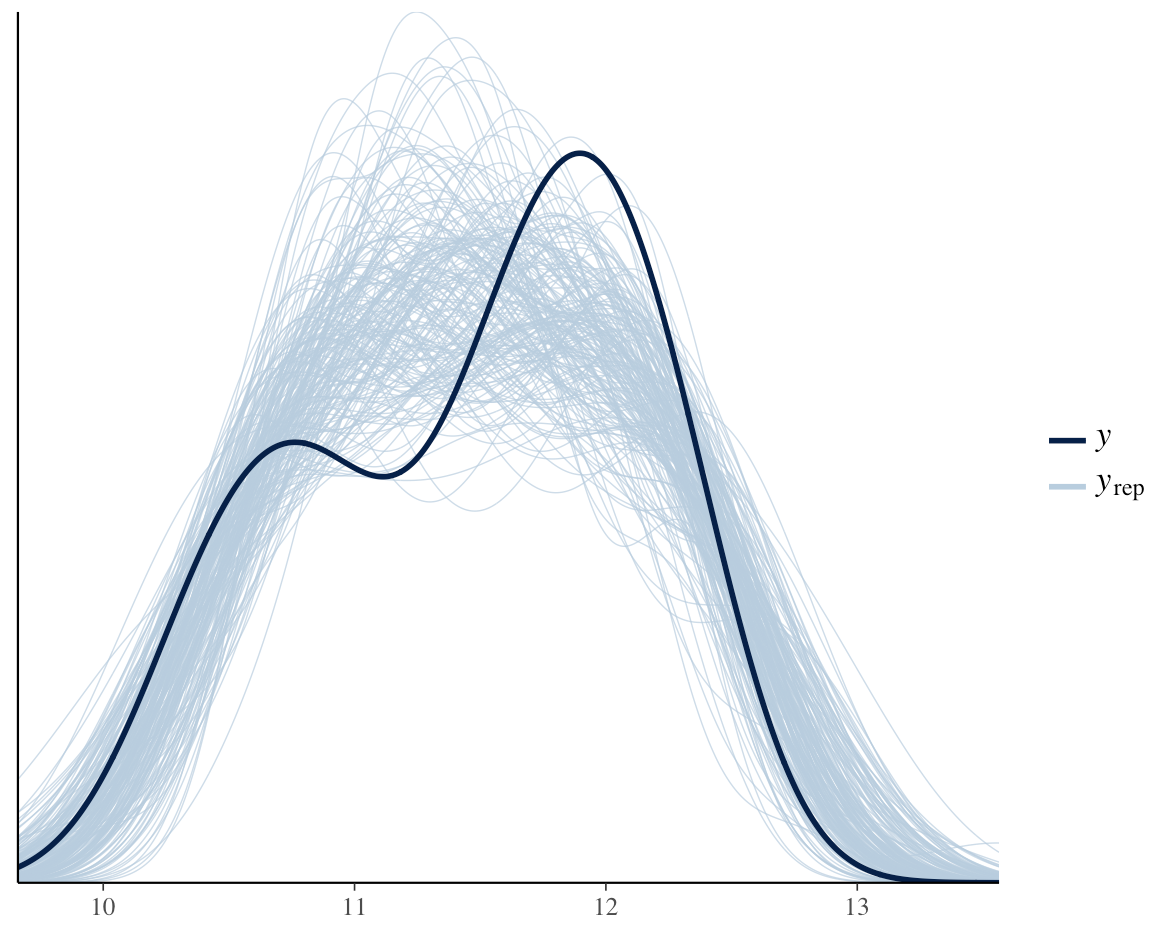 Figure 12. Comparing estimates across random posterior draws.
Figure 12. Comparing estimates across random posterior draws.
Here we see data (dark blue) fit well with our posterior predictions.
We can also use this to compare estimates of summary statistics.
ppc_stat(y = y, yrep = y_rep, stat = "mean")
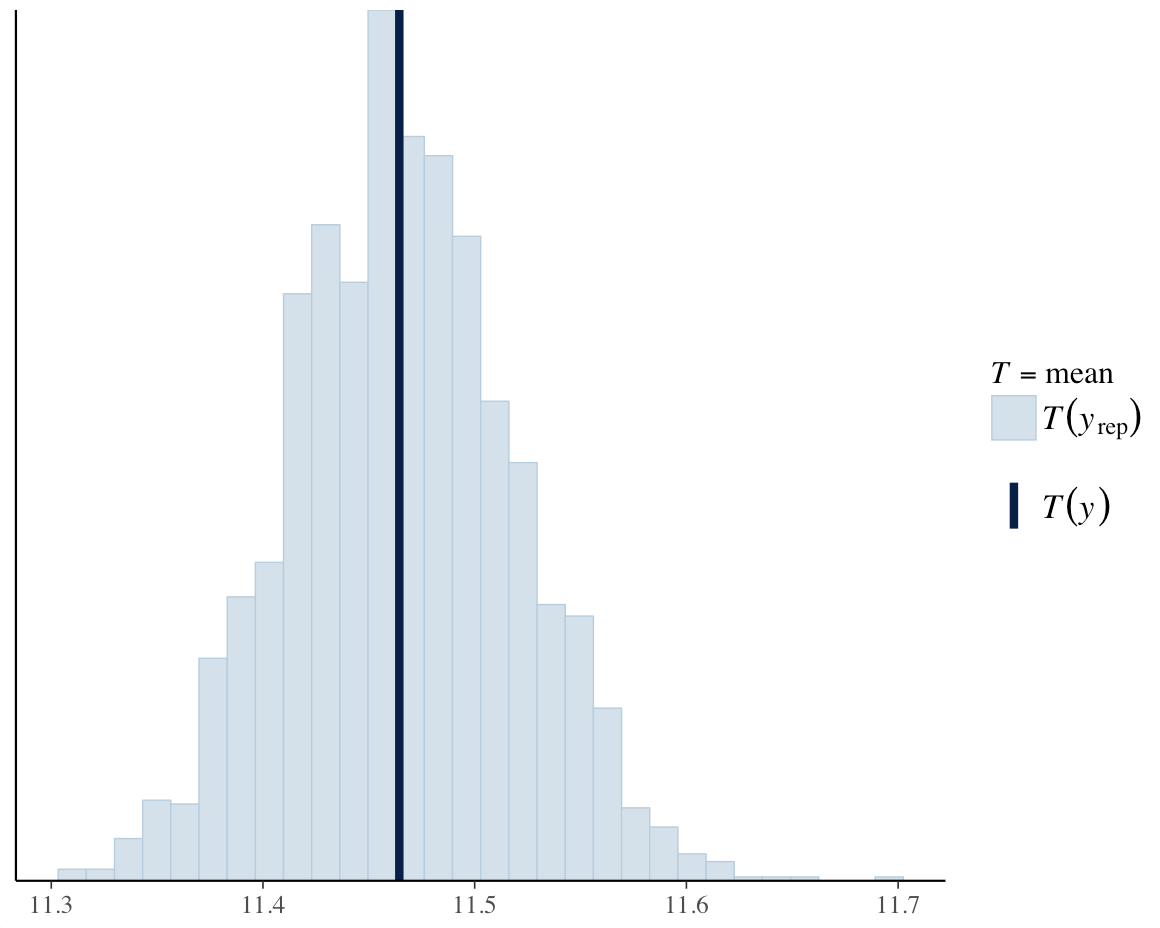 Figure 13. Comparing estimates of summary statistics.
Figure 13. Comparing estimates of summary statistics.
We can change the function passed to the stat function, and even write our own!
We can investigate mean posterior prediction per datapoint vs the observed value for each datapoint (default line is 1:1)
ppc_scatter_avg(y = y, yrep = y_rep)
Figure 14. Mean posterior prediction per datapoint vs the observed value for each datapoint.
bayesplot options
Here is a list of currently available plots (bayesplot 1.2):
available_ppc()
You can change the colour scheme in bayesplot too:
color_scheme_view(c("blue", "gray", "green", "pink", "purple",
"red","teal","yellow"))
And you can even mix them:
color_scheme_view("mix-blue-red")
You can set color schemes with:
color_scheme_set("blue")
So now you have learned how to run a linear model in Stan and to check the model convergence. But what is the answer to our research question?
Research Question: Is sea ice extent declining in the Northern Hemisphere over time?
What do your Stan model results indicate?
How would you write up these results? What is the key information to report from a Stan model? Effect sizes, credible intervals, sample sizes, what else? Check out some Stan models in the ecological literature to see how those Bayesian models are reported.
Now as an added challenge, can you go back and test a second research question:
Research Question: Is sea ice extent declining in the Southern Hemisphere over time?
Is the same pattern happening in the Antarctic as in the Arctic? Fit a Stan model to find out!
In the next Stan tutorial, we will build on the concept of a simple linear model in Stan to learn about more complex modelling structures including different distributions and random effects. And in a future tutorial, we will introduce the concept of a mixture model where two different distributions are modelled at the same time - a great way to deal with zero inflation in your proportion or count data!
Additional ways to run Stan models in R
Check out our second Stan tutorial to learn how to fit Stan models using model syntax similar to the style of other common modelling packages like lme4 and MCMCglmm, as well as how to fit generalised linear models using Poisson and negative binomial distributions.
Stan References
Stan is a run by a small, but dedicated group of developers. If you are new to Stan, you can join the mailing list. It’s a great resource for understanding and diagnosing problems with Stan, and by posting problems you encounter you are helping yourself, and giving back to the community.
- Stan website
- Stan manual (v2.14)
- Rstan vignette
- STANCON 2017 Intro Course Materials
- Statistical Rethinking by R. McElreath
- Stan mailing list
This tutorial is based on work by Max Farrell - you can find Max’s original tutorial here which includes an explanation about how Stan works using simulated data, as well as information about model verification and comparison.